
Data is (still) your lifeblood


In my previous post, I discussed how AI makes product development cheaper and faster than ever. When a competitor or new entrant can clone your product in weeks or months, how do you stay ahead in the game?
This post explores the first pillar of the 3D’s: Data.
I know the idea of data as a competitive advantage isn’t new — it goes way back to the rise of the dot-coms. Your local supermarket or store used to know nothing about you: who you are, what you buy, whether you splurge on some items at certain times. But with the move to online shopping, where every purchase was tied to your user account, stores suddenly had the ability to analyse your behavior and predict what you might want or need next. You might have heard that old story where a father complained to an online retailer for promoting pregnancy products to his teenage daughter — only to discover she was indeed pregnant, and the store’s algorithm had figured it out before he did.
Despite how long this idea has been around, I think it’s still worth writing about. The newer generation of founders and tech leaders are *shudder* young enough to be digital natives — they’ve never lived in a purely offline world — and might take data collection for granted.
What kind of data are we talking about?
When I say "data," I’m not talking about big numbers on a dashboard. I mean the specific, actionable data about your users: who they are, how they behave, and how they use your product to get their jobs done. Broadly, there are three main types of data you should care about:
1. Self-reported data
This is the information users provide directly. It could be their age, gender, date of birth, job role, company size, goals, or preferences — whatever you ask them during sign-up, onboarding, or later down the line. It’s the simplest type of data to collect, but it comes with limitations.
First, no one loves filling out forms, especially if they’re trying to get into your product quickly. Overdoing it at onboarding can hurt your activation funnel. Second, this data becomes outdated fast. Many tools ask for someone’s role at sign-up and never check in again. Roles and goals change, and stale data doesn’t help anyone.
2. Behavioral data
This is where things get more interesting. Instead of asking users what they think they do, you observe what they actually do. Which features do they use? How long are they spending on a specific workflow? What’s their typical path through the product? This kind of data gives you a clearer picture of user behavior and intent.
As a leader, it’s easy to assume you’re collecting everything automatically through your product. Hate to break it to you, but you’re probably not. Engineers don’t usually log every single action by default — it costs time, storage, and can slow the system down. If you want this data, you have to be intentional about defining what to track and why. Focus on the behaviors that drive value: those linked to activation, retention, and loyalty.
3. Unstructured user-generated content
Here’s where the game has really changed. Think of the content your users create within your product — notes, tasks, messages, comments. Just as an example, in tools like Asana or Trello, a task might have a title, a description, and associated comments that reveal rich context about the user’s goals. Historically, this kind of data was hard to tap into. It’s messy, inconsistent, and requires a lot of manual parsing to make sense of.
But with advances in large language models (LLMs), this barrier is crumbling. LLMs can process and structure this data at scale, turning messy content into clear insights. They can summarise, categorise, and even extract user intent based on what’s written. This is where you can unlock a level of product intelligence that goes far beyond surface-level interactions.
Other types of data: Metadata and industry data
While these three are the core types, there are two more types of data worth mentioning. Metadata — like device type, time of use, location — can add useful context, especially for performance optimization. And industry data (external benchmarks, market trends) can complement your internal insights, helping you understand where your product fits in the broader landscape. Used wisely, these can round out your data strategy.
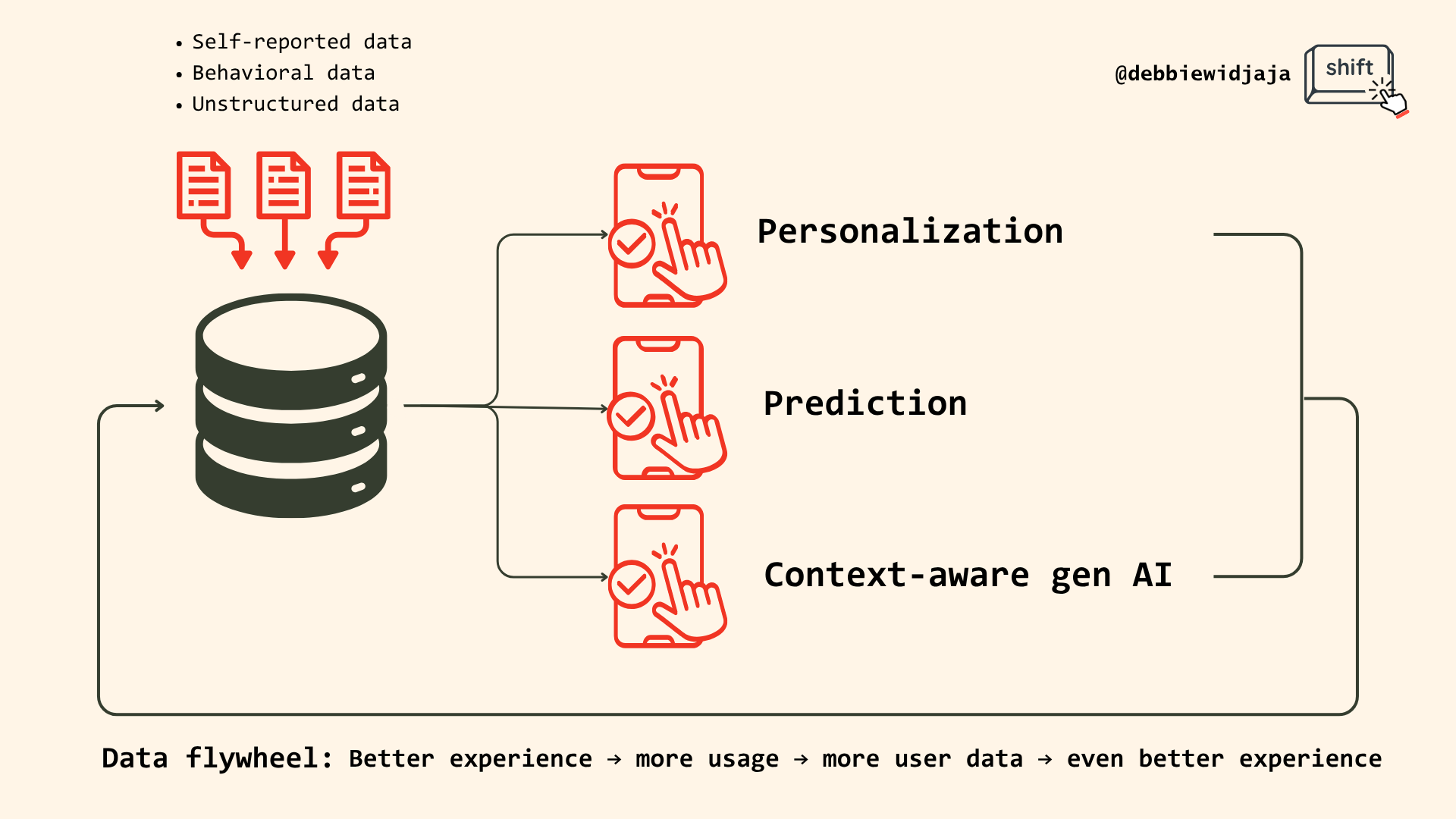
From data inputs to powerful outputs
Having data isn’t enough. The real advantage comes from how you use it to create a better product experience — one that’s smarter, more useful, and harder for competitors to copy. There are three big levers here:
1. Personalization
This is where data makes the user’s journey smoother. Based on what you know about them (inputted data) and what they actually do (behavioral data), you can recommend the next best action or suggest ways to improve their workflow. This can take many forms: suggesting the next best action, tailoring the interface to their habits, or offering recommendations on how to improve what they’re already doing.
Using Trello or Asana example again, it might suggest a template, pre-fill fields, or automate repetitive steps. These touches make the experience smoother and reduce friction — making your product more sticky.
2. Prediction
Prediction goes one step further. By analysing behavioral data at scale, you can identify patterns that signal what a user is likely to do next. Are they about to churn? Are they primed for an upsell? Are they stuck at a bottleneck?
With these insights, you can intervene proactively — offering help before frustration sets in, nudging users toward valuable features, or offering incentives at just the right moment. This kind of predictive capability not only improves the user experience but also drives key business outcomes like retention and expansion.
3. 10x better generative AI products
This is where the latest advances in AI come into play. While anyone can plug an off-the-shelf LLM into their product today, what makes your generative AI truly stand out is the context you can feed it.
A generic AI created by a new entrant will usually produce something too broad to be useful. But if your system already knows the user’s role, recent activity, preferred formats, and the specific project they’re working on, it can deliver a report that’s almost exactly what they need — without extra prompting from the user’s side.
Think of it like ordering at a restaurant. A user trying out a new AI product is like telling the waiter, “I’d like a meal, please.” You’ll get something, but it might not suit your preferences. A context-aware system is like the waiter knowing your dietary needs, favourite flavours, and portion size. In product terms, this means automating the context and providing it to the AI behind the scenes, creating a product experience that feels almost magical to the user.
The long game: Data flywheels and network effects
The magic of leveraging data isn’t just in the immediate improvements — it’s in the compounding advantage you build over time.
The data flywheel works like this: as your product collects more data, it learns and improves. Users then get more value, which encourages deeper engagement, generating even richer data. This creates a self-reinforcing loop that’s hard for competitors to catch up with. Competitors might copy features, but they won’t have the same depth of understanding about your users’ needs.
In collaborative or community-driven products, this advantage is amplified by network effects. As more users contribute data (structured or unstructured), the product becomes more valuable for everyone. Switching costs increase, not just because users are used to your interface, but because their data and workflows are embedded in your ecosystem — we’ll explore this a bit more in another post on Distribution.
Key takeaways
In a world where it’s easier than ever to spin up new products, data remains a key competitive advantage — if you know how to use it.
Start with a clear understanding of the proprietary data you have — inputted, behavioral, and unstructured — and complement it with metadata and external datasets where useful.
Use this data to deliver personalized experiences, predictive interventions, and context-rich generative AI to make your product frictionless.
Remember that data compounds. The more value you deliver, the more data you collect, and the harder it becomes for competitors to catch up. Combine this with network effects where possible, and you’ll build not just a better product, but a more defensible one.